

В современном мире технологий нейросети стали неотъемлемой частью нашей повседневной жизни. Они способны обрабатывать огромные объемы данных, анализировать информацию и выполнять сложные задачи, которые когда-то казались недостижимыми. В этой статье мы рассмотрим семь нейросетей, которые могут помочь вам стать более эффективными в различных сферах.
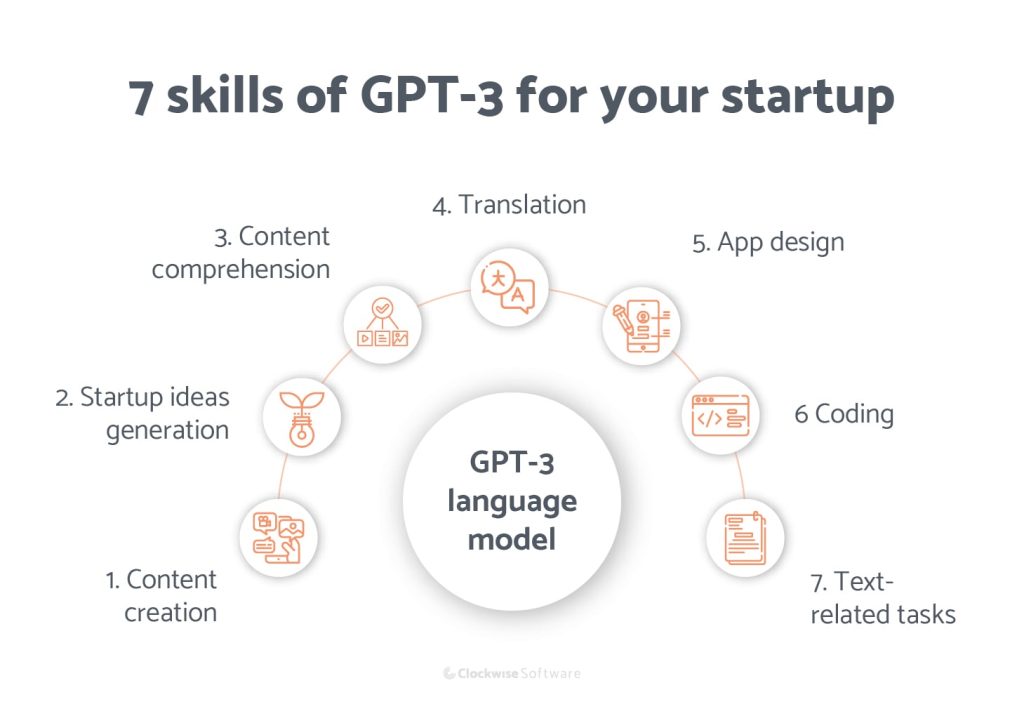
GPT-3 (Generative Pre-trained Transformer 3): Мощь Генеративных Преобученных Трансформеров
GPT-3, разработанный OpenAI, представляет собой внушительную языковую модель, основанную на архитектуре трансформеров. Эта нейронная сеть покорила мир искусственного интеллекта своей способностью генерировать тексты, имитировать стиль писателей и эффективно выполнять множество задач, взаимодействуя с текстовыми данными.
Принцип Работы GPT-3
GPT-3 основан на архитектуре трансформеров, которая позволяет обрабатывать последовательности данных, такие как тексты, с изумительной эффективностью. Модель состоит из множества слоев, называемых «трансформерами», которые работают с данными параллельно. Это позволяет ей обрабатывать даже самые длинные тексты, сохраняя важные зависимости между словами и фразами.
Преобучение и Трансфер Обучение
Одним из ключевых аспектов GPT-3 является его «преобученность». Модель обучается на огромных объемах текстовых данных перед тем, как начать выполнять конкретные задачи. Во время преобучения модель учится понимать языковые структуры, связи между словами и общий смысл текстов.
После этого GPT-3 подвергается «трансферному обучению», когда модель дообучается на конкретных задачах. Например, ее можно настроить на генерацию статей по медицинской тематике или даже на создание диалоговых интерфейсов. Это делает GPT-3 удивительно гибкой и способной выполнять разнообразные задачи.
Разнообразные Применения
GPT-3 нашла применение в различных областях. В сфере контента и маркетинга, модель может автоматически генерировать тексты, создавать заголовки, описания товаров и даже сочинять рекламные кампании. В образовании GPT-3 может служить инструментом для обучения и генерации учебных материалов.
Еще одной важной областью применения является создание диалоговых систем. GPT-3 может создавать натуральные ответы на вопросы пользователей, эмулировать разговоры с живыми собеседниками и даже помогать в обучении языку.
Вызовы и Будущее
Не смотря на впечатляющие достижения, у GPT-3 есть и некоторые ограничения. Например, модель иногда может генерировать неправдоподобные или некорректные ответы, и у нее отсутствует настоящее понимание контекста, как у человека.
В будущем мы можем ожидать дальнейшего развития языковых моделей, включая GPT-3. Возможно, будут созданы более сложные и улучшенные версии, способные лучше понимать контекст и генерировать более точные и креативные тексты.
ResNet (Residual Neural Network): Прорыв в Глубоком Обучении
ResNet, или Residual Neural Network, представляет собой инновационную архитектуру нейронных сетей, которая решила одну из наиболее серьезных проблем глубокого обучения – проблему затухающего градиента. Эта архитектура, предложенная в статье Kaiming He и его коллегами в 2015 году, стала важным прорывом в области компьютерного зрения и машинного обучения в целом.
Проблема Затухающего Градиента
При обучении глубоких нейронных сетей возникает проблема затухающего градиента. Это означает, что во время процесса обратного распространения ошибки градиент (производная функции ошибки по весам) начинает уменьшаться по мере прохождения назад по слоям сети. Как результат, глубокие сети становились сложнее обучать, и эффективность обучения начинала падать.
Блоки Остаточных Соединений
ResNet внедрил концепцию «блоков остаточных соединений», которые позволяют сети буквально «пропускать» информацию через слои. Вместо того чтобы пытаться научить сеть вычислять преобразование от входа к выходу, как это делается в традиционных нейронных сетях, блоки остаточных соединений пытаются научить сеть вычислять остаточные функции, то есть разницу между текущим состоянием и желаемым.
Это позволяет более глубоким сетям легче обучаться, так как в случае необходимости сеть может оставить информацию без изменений, минуя сложные преобразования. Блоки остаточных соединений также решают проблему затухающего градиента, так как они создают путь, по которому градиенты могут свободно передвигаться.
Вариации ResNet
С течением времени были разработаны различные вариации архитектуры ResNet, такие как ResNet-50, ResNet-101 и ResNet-152. Эти числа указывают на количество слоев в сети. Больше слоев обычно означает большую мощность, но также может привести к проблемам с обучением из-за градиентов.
Применение в Обработке Изображений
ResNet и его вариации стали популярными в компьютерном зрении и обработке изображений. Они показали впечатляющие результаты в задачах классификации изображений, обнаружении объектов, сегментации и многих других. Это позволило создавать более глубокие и эффективные модели для анализа визуальных данных
LSTM (Long Short-Term Memory): Сохранение Долгосрочных Зависимостей в Нейронных Сетях
LSTM, или Long Short-Term Memory, является одним из наиболее важных и инновационных разработок в области рекуррентных нейронных сетей (RNN). Она была предложена Сеппо Лахтаненом, Юргеном Шмидхубером и Фредериком Герфа в 1997 году и с тех пор сыграла ключевую роль в обработке последовательных данных, таких как тексты, временные ряды и речь.
Проблема Затухания/Взрывающегося Градиента
Рекуррентные нейронные сети представляют собой класс нейронных сетей, которые могут сохранять информацию о предыдущих состояниях для обработки последовательных данных. Однако они сталкиваются с проблемой затухания и взрывающегося градиента, когда градиенты (производные) могут становиться слишком маленькими или слишком большими в процессе обратного распространения ошибки, что затрудняет обучение на глубоких последовательных сетях.
Структура LSTM
LSTM решает проблему затухания и взрывающегося градиента, предоставляя механизмы для эффективной работы с долгосрочными зависимостями в последовательных данных. Основная идея состоит в использовании специальных «ячеек памяти», которые могут сохранять информацию на долгий период времени. Каждая ячейка памяти имеет три ключевых компонента:
- Забывающий вентиль (Forget Gate): Определяет, какая информация будет удалена из ячейки памяти. Это позволяет сети «забывать» ненужные или устаревшие данные.
- Входной вентиль (Input Gate): Решает, какие новые данные будут добавлены в ячейку памяти.
- Выходной вентиль (Output Gate): Определяет, какая информация из ячейки памяти будет использована для создания выхода сети.
Эти компоненты позволяют LSTM эффективно управлять информацией и долгосрочными зависимостями в данных.
Применение LSTM
LSTM нашли широкое применение в обработке текстов, где они способны улавливать зависимости между словами в долгосрочной перспективе. Они также успешно применяются в задачах временных рядов, таких как прогнозирование, анализ финансовых данных и управление временными последовательностями.
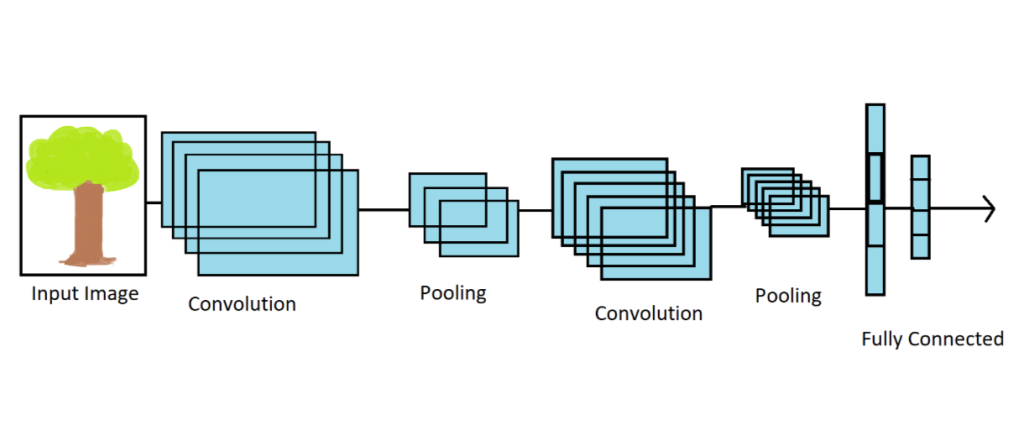
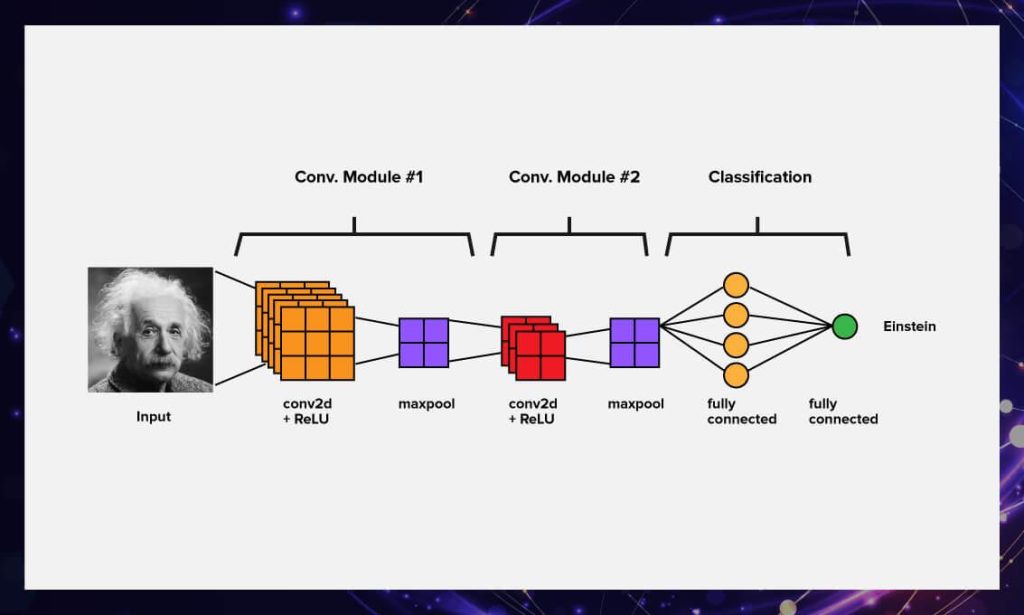
CNN (Convolutional Neural Network): Прорыв в Обработке Изображений
Сверточные нейронные сети (CNN), иногда называемые ConvNets, являются одними из самых влиятельных достижений в области обработки изображений и компьютерного зрения. Они революционизировали способ, которым мы анализируем и понимаем визуальные данные, и сыграли ключевую роль в достижении выдающихся результатов в распознавании образов, классификации изображений и других задачах компьютерного зрения.
Принцип Работы CNN
CNN основаны на двух ключевых идеях: свертка и пулинг. Свертка позволяет сети автоматически извлекать характеристики изображений, обнаруживать края, текстуры и другие важные детали. Пулинг (или субдискретизация) позволяет уменьшить размерность данных, сохраняя важные информационные аспекты и улучшая вычислительную эффективность.
Слои CNN
Основные составляющие CNN – это сверточные слои и слои пулинга. Сверточные слои используют фильтры (ядра свертки), которые проходят через изображение, усиливая или подавляя определенные характеристики. Пулинг-слои сжимают информацию, выбирая наиболее значимые значения из регионов изображения.
Иерархическое Извлечение Характеристик
Одна из ключевых особенностей CNN – это способность иерархически извлекать характеристики изображения. Первые слои могут обнаруживать базовые детали, такие как грани и текстуры, в то время как последующие слои абстрагируют более высокоуровневые понятия, такие как формы и объекты. Эта иерархия позволяет сети постепенно строить сложные исходные представления изображений.
Применение в Компьютерном Зрении
CNN нашли широкое применение в задачах компьютерного зрения. Они успешно применяются для классификации изображений (например, распознавание животных или транспорта), детектирования объектов (обнаружение лиц, машин и других объектов), сегментации изображений (разделение изображения на части, например, для выделения объектов на фоне) и даже в генерации изображений.
Transformer: Революция в Обработке Последовательностей
Transformer – это архитектура нейронных сетей, предложенная в статье «Attention is All You Need» в 2017 году, которая стала точкой отсчета для многих современных языковых моделей. Его ключевая инновация – механизм внимания (attention), который позволяет модели эффективно работать с последовательностями данных, такими как тексты, без необходимости использовать рекуррентные связи.
Механизм Внимания
Вместо того чтобы полагаться на последовательное обработку данных, как делают рекуррентные нейронные сети, Transformer использует механизм внимания для прямого взаимодействия между элементами последовательности. Это позволяет сети одновременно учитывать зависимости между всеми элементами, что способствует эффективному обучению и созданию более точных моделей.
Слои и Применение
Transformer состоит из множества слоев, каждый из которых содержит подслои механизма внимания и полносвязные слои. Он может быть применен для различных задач, таких как машинный перевод, генерация текста, анализ сентимента и многие другие. Помимо языковых данных, Transformer также успешно используется в задачах обработки звука и временных рядов.
DQN (Deep Q-Network): Обучение с Подкреплением на Примере Игр
DQN, или Deep Q-Network, представляет собой алгоритм обучения с подкреплением, разработанный компанией DeepMind, который стал важным прорывом в применении нейронных сетей к задачам игр и управления агентами в виртуальных средах.
Обучение с Подкреплением
Обучение с подкреплением – это метод машинного обучения, в котором агент принимает решения в среде, чтобы максимизировать некоторую награду. DQN применяется к таким задачам как игры Atari и другие видеоигры, где агенту необходимо научиться выбирать действия, чтобы максимизировать сумму получаемых очков.
Q-функция и Deep Q-Network
Центральной концепцией DQN является Q-функция, которая оценивает ожидаемую сумму вознаграждений, которую агент может получить, выбирая определенные действия в определенных состояниях. DQN использует нейронные сети для аппроксимации Q-функции, исследуя различные действия в среде и обновляя свои оценки на основе наград и новых состояний.
Применение в Играх
DQN и его вариации стали известными своими успешными результатами в задачах игр. Они способны обучать агентов, которые могут достигать или даже превзойти уровень человеческих игроков в различных видеоиграх, используя только наблюдаемые данные об игре (изображения экрана, численные данные и т.д.).
GAN (Generative Adversarial Network): Искусство Генерации и Дискриминации
Generative Adversarial Network (GAN) – это уникальная архитектура нейронных сетей, предложенная Ианом Гудфеллоу и его коллегами в 2014 году, которая стала одной из самых важных идей в генеративном искусстве и машинном обучении. Основной идеей GAN является принцип «игры» между двумя сетями – генератором и дискриминатором – которые соревнуются друг с другом.
Принцип Работы GAN
GAN состоит из двух основных компонентов: генератора и дискриминатора. Генератор создает новые данные, например, изображения, а дискриминатор старается определить, являются ли эти данные реалистичными (подлинными) или созданными генератором.
Процесс обучения GAN начинается с того, что генератор создает поддельные данные. Дискриминатор затем анализирует их и пытается различить, какие данные реальные, а какие – сгенерированные. Генератор затем пытается улучшить свои навыки, чтобы обмануть дискриминатора, создавая более реалистичные данные. Процесс продолжается до тех пор, пока генератор не станет настолько хорош, что дискриминатор начинает трудно различать подлинные данные от сгенерированных.
Применение GAN
GAN нашли применение во многих областях. В компьютерном зрении, они используются для генерации реалистичных изображений, улучшения разрешения фотографий, создания арт-портретов и даже для преобразования стилей изображений.
В генеративном искусстве GAN позволяют создавать новые, оригинальные произведения, сочетая стили различных художников или стилей. Они также используются в музыке для создания новых мелодий и звуков.
GAN также нашли свое место в генерации текста. Они могут создавать автоматические ответы в диалоговых системах, генерировать новости, статьи и даже литературные тексты.
Вызовы и Перспективы
Хотя GAN предоставляют удивительные результаты, они также имеют свои сложности. Например, неконтролируемое обучение GAN может привести к генерации содержания, которое нежелательно или даже оскорбительно. Также сложно оценить качество генерируемых данных, так как нет явных метрик.
В будущем можно ожидать развитие более сложных и улучшенных вариаций GAN, которые будут лучше контролировать процесс генерации и сделают машинное творчество еще более реалистичным и интересным.
Conclusion
В заключение, нейросети стали мощными инструментами, способными повысить эффективность в различных сферах. От обработки данных и автоматизации до анализа текстов и генерации контента – эти семь нейросетей предоставляют нам уникальные возможности для достижения новых высот в нашей работе и творчестве.




