

In today's technological world, neural networks have become an integral part of our daily lives. They can process massive amounts of data, analyze information, and perform complex tasks that once seemed impossible. In this article, we'll look at seven neural networks that can help you become more effective in various fields.
GPT-3 (Generative Pre-trained Transformer 3): The Power of Generative Pre-trained Transformers
GPT-3, developed by OpenAI, is a powerful language model based on the Transformer architecture. This neural network has taken the AI world by storm with its ability to generate text, imitate writers' styles, and efficiently perform a variety of tasks when interacting with text data.
How GPT-3 Works
GPT-3 is based on a transformer architecture that enables it to process sequences of data, such as text, with remarkable efficiency. The model consists of multiple layers, called "transformers," that process the data in parallel. This allows it to process even the longest texts while preserving important relationships between words and phrases.
Pre-training and Transfer Training
One of the key aspects of GPT-3 is its "pretraining." The model is trained on massive amounts of text data before being introduced to specific tasks. During pretraining, the model learns to understand linguistic structures, word relationships, and the overall meaning of texts.
GPT-3 then undergoes "transfer learning," where the model is further trained on specific tasks. For example, it can be configured to generate medical articles or even create conversational interfaces. This makes GPT-3 remarkably flexible and capable of performing a wide variety of tasks.
Diverse Applications
GPT-3 has found applications in a variety of fields. In content and marketing, the model can automatically generate text, create headlines, product descriptions, and even design advertising campaigns. In education, GPT-3 can serve as a tool for training and generating educational materials.
Another important area of application is the creation of dialogue systems. GPT-3 can generate natural responses to user questions, emulate conversations with live interlocutors, and even assist in language learning.
Challenges and the Future
Despite its impressive achievements, GPT-3 does have some limitations. For example, the model can sometimes generate implausible or incorrect answers, and it lacks a true understanding of context like a human.
In the future, we can expect further development of language models, including GPT-3. More complex and improved versions may be created, capable of better understanding context and generating more accurate and creative texts.
ResNet (Residual Neural Network): A Breakthrough in Deep Learning
ResNet, or Residual Neural Network, is an innovative neural network architecture that has solved one of the most challenging problems in deep learning—the vanishing gradient problem. Proposed in a 2015 paper by Kaiming He and his colleagues, this architecture marked a significant breakthrough in computer vision and machine learning in general.
The Problem of the Evanescent Gradient
When training deep neural networks, the problem of vanishing gradient arises. This means that during the backpropagation process, the gradient (the derivative of the error function with respect to the weights) begins to decrease as it passes backward through the network layers. As a result, deep networks become more difficult to train, and training efficiency begins to decline.
Residual Connection Blocks
ResNet introduced the concept of "residual connection blocks," which allow the network to literally "pass" information through layers. Instead of trying to teach the network to compute the input-to-output transformation, as is done in traditional neural networks, residual connection blocks attempt to teach the network to compute residual functions, that is, the difference between the current state and the desired one.
This allows deeper networks to be trained more easily, as the network can leave information unchanged if necessary, bypassing complex transformations. Residual connection blocks also solve the vanishing gradient problem by creating a path along which gradients can move freely.
Variations of ResNet
Over time, various variations of the ResNet architecture have been developed, such as ResNet-50, ResNet-101, and ResNet-152. These numbers indicate the number of layers in the network. More layers generally mean more power, but can also lead to training issues due to gradients.
Application in Image Processing
ResNet and its variations have become popular in computer vision and image processing. They have demonstrated impressive results in image classification, object detection, segmentation, and many other tasks. This has enabled the creation of deeper and more efficient models for visual data analysis.
LSTM (Long Short-Term Memory): Preserving Long-Term Dependencies in Neural Networks
LSTM, or Long Short-Term Memory, is one of the most important and innovative developments in the field of recurrent neural networks (RNNs). It was proposed by Seppo Lahtanen, Jürgen Schmidhuber, and Frederik Gerfa in 1997 and has since played a key role in processing sequential data such as text, time series, and speech.
The Gradient Fade/Explode Problem
Recurrent neural networks are a class of neural networks that can retain information about previous states to process sequential data. However, they face the problem of gradient decay and exploding gradients, where gradients (derivatives) can become too small or too large during backpropagation, making training on deep sequential networks difficult.
LSTM structure
LSTM solves the problem of gradient decay and exploding gradients by providing mechanisms for efficiently handling long-term dependencies in sequential data. The basic idea is to use special "memory cells" that can retain information over long periods of time. Each memory cell has three key components:
- Forget Gate: Determines which information will be removed from a memory cell. This allows the network to "forget" unnecessary or obsolete data.
- Input Gate: Decides what new data will be added to the memory cell.
- Output Gate: Determines which information from the memory cell will be used to create the network output.
These components allow LSTM to efficiently manage information and long-term dependencies in the data.
Application of LSTM
LSTMs have found widespread application in text processing, where they are capable of capturing long-term relationships between words. They are also successfully applied to time series tasks, such as forecasting, financial data analysis, and time series management.
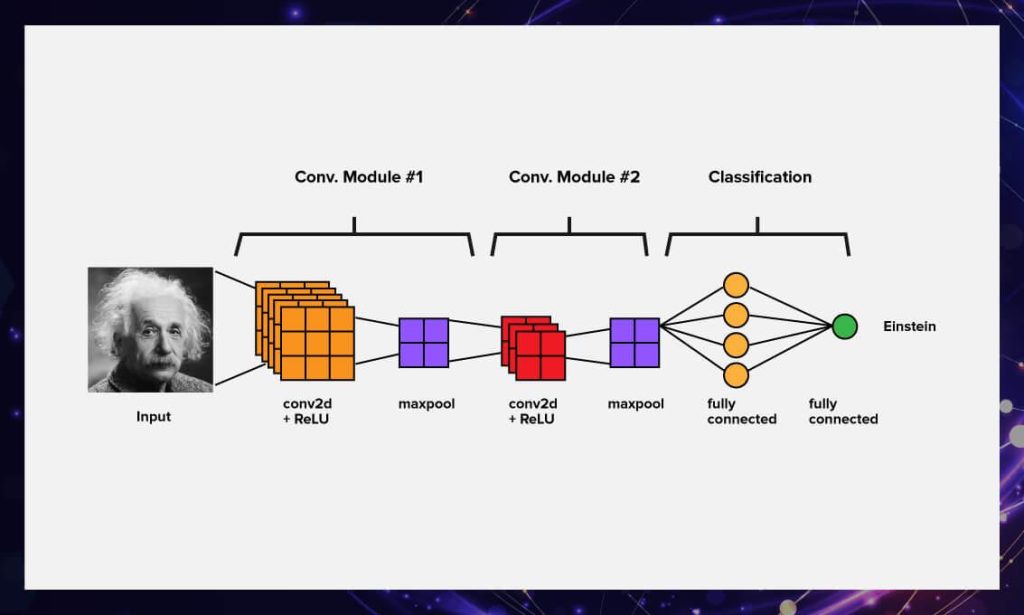
CNN (Convolutional Neural Network): A Breakthrough in Image Processing
Convolutional neural networks (CNNs), sometimes called ConvNets, are among the most influential advances in image processing and computer vision. They have revolutionized the way we analyze and understand visual data and have played a key role in achieving remarkable results in pattern recognition, image classification, and other computer vision tasks.
How CNN Works
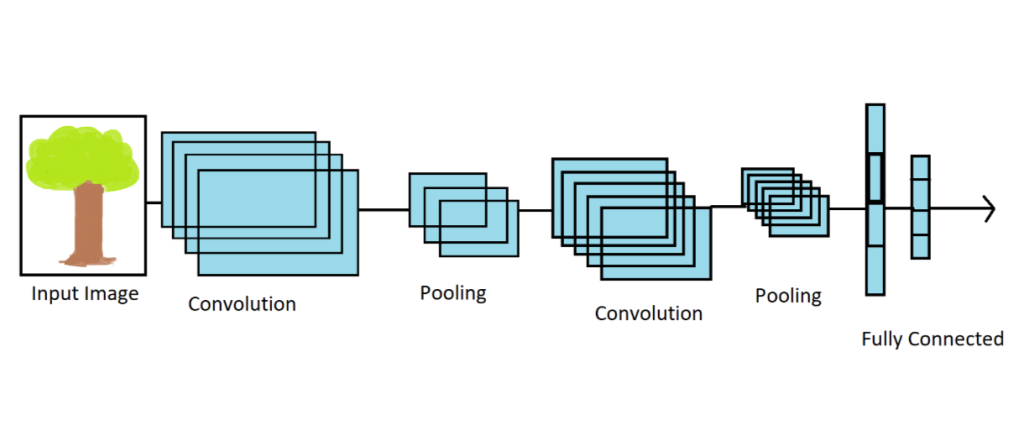
Convolutional neural networks (CNNs) are based on two key concepts: convolution and pooling. Convolution allows the network to automatically extract image features, detecting edges, textures, and other important details. Pooling (or downsampling) reduces the dimensionality of the data, preserving important information aspects and improving computational efficiency.
CNN layers
The main components of a CNN are convolutional layers and pooling layers. Convolutional layers use filters (convolution kernels) that pass through the image, enhancing or suppressing certain features. Pooling layers compress information by selecting the most significant values from image regions.
Hierarchical Feature Extraction
One of the key features of CNNs is their ability to hierarchically extract image features. Early layers can detect basic details such as edges and textures, while subsequent layers abstract higher-level concepts such as shapes and objects. This hierarchy allows the network to gradually build complex initial representations of images.
Application in Computer Vision
Convolutional neural networks (CNNs) have found wide application in computer vision. They are successfully used for image classification (for example, animal or vehicle recognition), object detection (detecting faces, cars, and other objects), image segmentation (dividing an image into parts, for example, to distinguish objects from the background), and even image generation.
Transformer: A Revolution in Sequence Processing
Transformer is a neural network architecture proposed in the 2017 paper "Attention is All You Need" that has become a benchmark for many modern language models. Its key innovation is its attention mechanism, which allows the model to effectively work with sequential data, such as text, without the need for recurrent relations.
Attention Mechanism
Instead of relying on sequential processing of data, as recurrent neural networks do, Transformer uses an attention mechanism for direct interactions between elements in a sequence. This allows the network to simultaneously consider the dependencies between all elements, facilitating efficient training and the creation of more accurate models.
Layers and Application
Transformer consists of multiple layers, each containing attention sublayers and fully connected layers. It can be applied to a variety of tasks, such as machine translation, text generation, sentiment analysis, and many others. In addition to language data, Transformer has also been successfully used in audio and time series processing.
DQN (Deep Q-Network): Reinforcement Learning from Games
DQN, or Deep Q-Network, is a reinforcement learning algorithm developed by DeepMind that has made a significant breakthrough in the application of neural networks to gaming and agent control tasks in virtual environments.
Reinforcement learning
Reinforcement learning is a machine learning method in which an agent makes decisions in an environment to maximize a given reward. DQN is applied to problems such as Atari and other video games, where the agent must learn to choose actions to maximize its score.
Q-function and Deep Q-Network
The central concept of DQN is the Q-function, which estimates the expected rewards an agent can receive by choosing certain actions in certain states. DQN uses neural networks to approximate the Q-function by exploring various actions in the environment and updating its estimates based on rewards and new states.
Application in Games
DQN and its variations have become renowned for their successful results in gaming tasks. They are capable of training agents that can reach or even surpass the skill of human players in various video games using only observed game data (screenshots, numerical data, etc.).
GAN (Generative Adversarial Network): The Art of Generation and Discrimination
The Generative Adversarial Network (GAN) is a unique neural network architecture proposed by Ian Goodfellow and his colleagues in 2014, which has become one of the most important ideas in generative learning and machine learning. The core idea of a GAN is the principle of a "game" between two networks—a generator and a discriminator—that compete with each other.
How GAN Works
A GAN consists of two main components: a generator and a discriminator. The generator creates new data, such as images, and the discriminator tries to determine whether this data is realistic (authentic) or created by the generator.
The GAN training process begins with the generator creating fake data. The discriminator then analyzes it and attempts to distinguish between real and generated data. The generator then attempts to improve its skills to fool the discriminator by creating more realistic data. The process continues until the generator becomes so good that the discriminator has difficulty distinguishing between genuine and generated data.
Applications of GANs
GANs have found application in many fields. In computer vision, they are used to generate realistic images, improve photo resolution, create fine art portraits, and even transform image styles.
In generative art, GANs enable the creation of new, original works by combining the styles of different artists or styles. They are also used in music to create new melodies and sounds.
GANs have also found their place in text generation. They can create automatic responses in dialog systems, generate news, articles, and even literary texts.
Challenges and Prospects
While GANs produce amazing results, they also have their challenges. For example, unsupervised GAN training can generate content that is objectionable or even offensive. It's also difficult to assess the quality of the generated data, as there are no explicit metrics.
In the future, we can expect the development of more complex and improved variations of GANs that will better control the generation process and make machine creativity even more realistic and interesting.
Conclusion
In conclusion, neural networks have emerged as powerful tools capable of boosting efficiency in a variety of fields. From data processing and automation to text analysis and content generation, these seven neural networks offer us unique opportunities to achieve new heights in our work and creativity.




